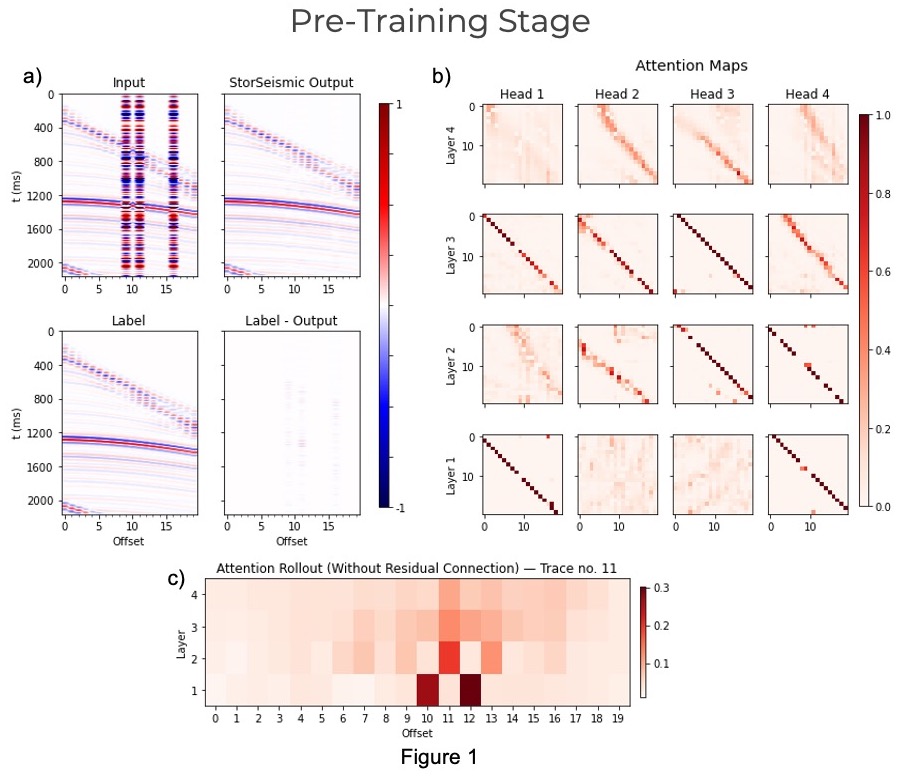
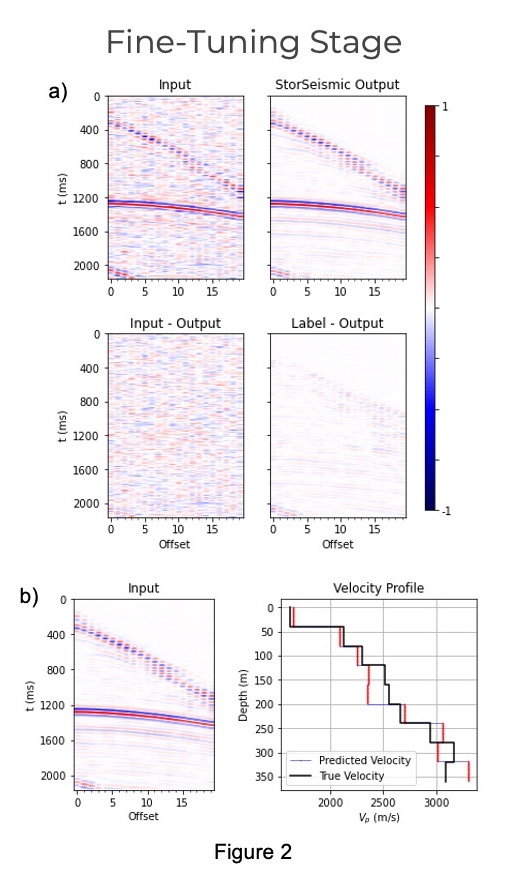
StorSeismic: An approach to pre-train a neural network to store seismic data features (Caesario, M.R., and Alkhalifah, T., 2022)
Through the help of the self-attention mechanism embedded in the Bidirectional Encoder Representation from Transformers (BERT), a Transformer-based network architecture which was originally developed for Natural Language Processing (NLP) tasks, we capture and store the local and global features of seismic data in the pre-training stage, then utilize them in various seismic processing tasks in the fine-tuning stage.
References
Caesario, M.R., and Alkhalifah, T., 2022, "StorSeismic: An approach to pre-train a neural network to store seismic data features", submitted to the 83rd EAGE Annual Conference and Exhibition.
Caesario, M.R., and Alkhalifah, T., 2022, "StorSeismic: An approach to pre-train a neural network to store seismic data features", submitted to the 83rd EAGE Annual Conference and Exhibition.